Машинное обучение в прогнозировании спроса: разбираемся в подходе
Алгоритмы машинного обучения давно используются в задачах, где на целевой показатель влияет множество факторов. Бустинговые модели на основе решающих деревьев, рекуррентные нейронные сети и другие методы позволяют учитывать сложные зависимости между признаками и адаптируются под широкий спектр бизнес‑сценариев. Эти же алгоритмы могут применяться и для прогнозирования временных рядов, но с определёнными особенностями.
Что такое временной ряд и почему он требует отдельного подхода
Временной ряд — это данные, упорядоченные во времени. История погоды, курс валют, продажи товара по дням — всё это примеры временных рядов. Их ключевая особенность в том, что порядок наблюдений имеет значение. Именно упорядоченная последовательность позволяет увидеть сезонность, циклы, тренды и другие закономерности, которые невозможно обнаружить в перемешанных данных.
Для работы с такими данными существуют два больших класса методов:
- классические авторегрессионные модели, которые используют только прошлые значения ряда;
- модели машинного обучения, которые можно адаптировать под временные ряды, добавляя необходимые признаки и структуру.
Как работает классическая регрессионная задача в ML
Чтобы понять разницу, рассмотрим задачу, не связанную со временем. Допустим, нужно предсказать рост человека по признакам: пол, возраст, страна проживания, вес. Каждый признак помогает модели уточнить прогноз. Алгоритм ищет зависимости между входными параметрами и целевой переменной, и порядок строк в таблице никак не влияет на результат.
В классических регрессионных задачах, в отличие от задач прогнозирования временных рядов:
- наблюдения независимы,
- нет циклов,
- нет сезонности,
- нет временной структуры.
Поэтому классические ML‑алгоритмы работают с ними «из коробки».
Что меняется при прогнозировании временных рядов
В прогнозировании продаж или спроса ситуация другая. Порядок наблюдений становится критически важным, потому что модель должна учитывать динамику:

Чтобы ML‑модель могла работать с такими данными, их необходимо подготовить:
- упорядочить по времени,
- добавить лаги (значения за предыдущие дни),
- сформировать скользящие окна (например, средние за неделю, две, месяц),
- включить календарные признаки (день недели, месяц, праздники),
- при необходимости — внешние факторы (погода, маркетинг, цены конкурентов).
Все признаки перечисленные выше должны быть подготовлены таким образом, чтобы у них была такая же структура временных рядов, как и у прогнозируемой величины. На каждый день у нас должны быть записи значений всех признаков (факторов), которые помогают лучше прогнозировать неизвестную нам величину.
Конкретный пример: прогнозируемая величина – продажи, факторы – погода, день недели, праздники, акции.
Как обучать модель
Предположим, мы собрали таблицу с продажами, которые мы хотим прогнозировать, и факторами, которые, по экспертному мнению, должны влиять на них. На каждый день у нас имеются значения продаж и всех факторов, которые на них могут повлиять. Тогда наш алгоритм будет представлен простой формулой:
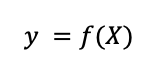
Где у – прогноз, f – алгоритм, X – данные по момент времени t. Суть обучения модели f заключается в том, чтобы по предоставленным данным алгоритм давал наименьшую ошибку.
Для создания прогнозного алгоритма необходимо:
- Подготовить все необходимые данные
- Выбрать алгоритм или набор алгоритмов для прогнозирования
- Разбить данные на обучающую и тестовую выборку
- Обучить и настроить модель
- Оценить метрики качества модели тестовой выборке
- Сравнить метрики модели с метриками простых классических моделей
Зачем разбираться в методологии
Понимание того, как обучаются модели, позволяет корректно оценивать их применимость. Некоторые ограничения связаны не с алгоритмами как таковыми, а с природой данных: длиной истории, регулярностью продаж, качеством признаков, наличием внешних факторов.
О некоторых ограничениях мы рассказывали в нашей предыдущей статье Когда прошлое не похоже на будущее: ограничения моделей прогнозирования в эпоху “чёрных лебедей”
Машинное обучение хорошо справляется там, где на показатель влияет множество факторов, где важна масштабируемость и где данные достаточно богаты, чтобы модель могла увидеть закономерности. Но ML‑подходы требуют дисциплины: аккуратной подготовки признаков, регулярного обновления моделей и прозрачной инфраструктуры вокруг них.
Когда эти условия соблюдены, машинное обучение становится надёжным инструментом для прогнозирования спроса, продаж, трафика и других бизнес‑метрик. Оно не заменяет экспертизу, но позволяет опираться на данные в тех ситуациях, где интуиции уже недостаточно. Именно поэтому ML‑прогнозирование сегодня — рабочая технология, которая приносит измеримую пользу компаниям, готовым инвестировать в качество данных и инженерный процесс.
Дополнительно
Почему точный прогноз спроса не гарантирует корректный автозаказ для розничной сети
Машинное обучение для прогнозирования спроса: план внедрения
Алгоритмы вместо интуиции: как оптимизировать производственное планирование